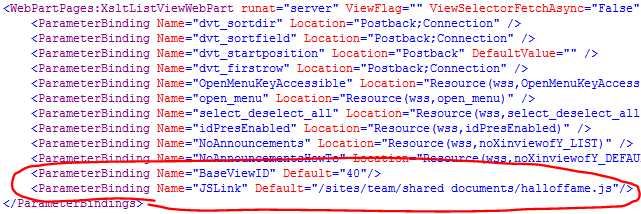
Applies To: PDF Manipulation
The Adobe Portable Document Format (PDF) has a ton of features but often they seem locked behind pay walls such as Acrobat Pro or 3rd party software/utilities. Fortunately, Adobe created a syntax to tap into many of these features called pdfmark. Pdfmark lets you do things like add bookmarks, annotations, document properties, links, attachments, and more! In this post I’ll introduce you to basic pdfmark syntax and show you how to apply it via the command line.
I’ve often been tasked with doing this sort of thing to 1,000s of documents. There are PDF libraries, opensource and otherwise, that you can add to some custom code but they often have poor documentation, strange support, and various levels of cost.
Fortunately, I’m going to show you how to get started writing your own pdfmark files and applying them from the command line with the free GhostScript tool! From there it’s relatively simple to batch process 1,000s of documents or integrate it into your own tool.
This post will serve as a basic setup guide for a short series on different things you can do with pdfmark.
Getting GhostScript
GhostScript is a free opensource library with a command line interface that makes it really easy to apply your pdfmark markup to any PDF with a simple command and it can be automated to process thousands of files. You may even have it installed already since it’s used by a lot of software (like PDF Printers). If not, it’s a pretty simple install.
Head over to the downloads page and pick either the 64 or 32 bit version depending on your machine. Unless you want tech support or want to redistribute GhostScript commercially, you can get the free one. As of this post, the latest version was 9.21.
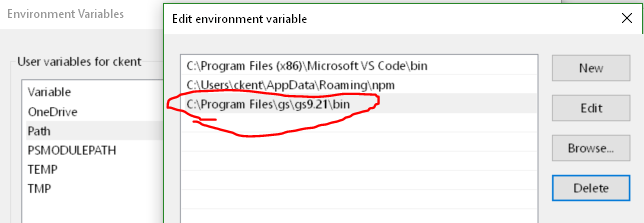
After you’ve installed GhostScript, you’ll want to add it to your PATH variable so that you can easily call it within any folder from the command line. The easiest way to do this on windows 10 is to type Environment Variables in the Cortana prompt and then double-click the Path variable, click New, and paste the path to the bin directory. Your actual path may be different depending on where you installed it:
Basic pdfmark
GhostScript will apply pdfmark syntax to a PDF document by referencing a text file. So let’s create a pdfmark text file!
Just open up notepad or whatever editor you prefer and type the following:
[ /PageMode /UseOutlines
/Page 1
/View [/Fit]
% I'm a comment!
/DOCVIEW pdfmark
This is an example of applying View Options to a PDF document and is one of the simplest things you can do.
Structure
Every pdfmark “command” starts with a left square bracket and ends with the command type preceded by a forward slash followed by the word pdfmark. Frustratingly, there is no closing square bracket (WHY?!).
You can have multiple commands in a single file.
Whitespace
In a pdfmark document, spaces and tabs don’t matter (except in strings which are enclosed in parenthesis and not shown above). This means that you could write it all on one line or do what I did and separate it across multiple lines and indent in a way that makes it easier to read.
Comments
You can add comments by using a % sign. The comment will apply until the end of the line and won’t be interpreted at all. Multi-line comments must each have a %.
Applying pdfmark to a PDF Document
Here’s the basic syntax for applying a pdfmark text file to a PDF document:
gswin64c -o [outputfilename] -sDEVICE=pdfwrite -dPDFSETTINGS=/prepress [originalPDFfilename] [pdfmarkfillename]
Note – GhostScript can do a ton of things and there are lots of additional options you can mix in to do some really powerful stuff, but the above is all you need to apply pdfmark.
If you just want to overwrite the PDF document, skip the -o parameter. Also, note that the parameters are CASE SENSITIVE.
Here’s an example of applying pdfmark to the MyPDF.pdf document using the pdfmark.txt file and saving the result as MySuperPDF.pdf:
gswin64c -o MySuperPDF.pdf -sDEVICE=pdfwrite -dPDFSETTINGS=/prepress MyPDF.pdf pdfmark.txt
Great! Now we can apply pdfmark to PDF files using the command line! But what can we do with it? The next few posts will provide several examples of what you can do. In the meantime, check out the pdfmark Reference, the PDF Reference, and/or the really helpful Cooking up Enhanced PDF with pdfmark Recipes eBook by Lynn Mead.